Entity Resolution Challenges
Entity Resolution (also known as Record Linkage, Deduplication etc) is the process of identifying the same entity (person, company, product etc) across one or more datasets and combining them into a single record.
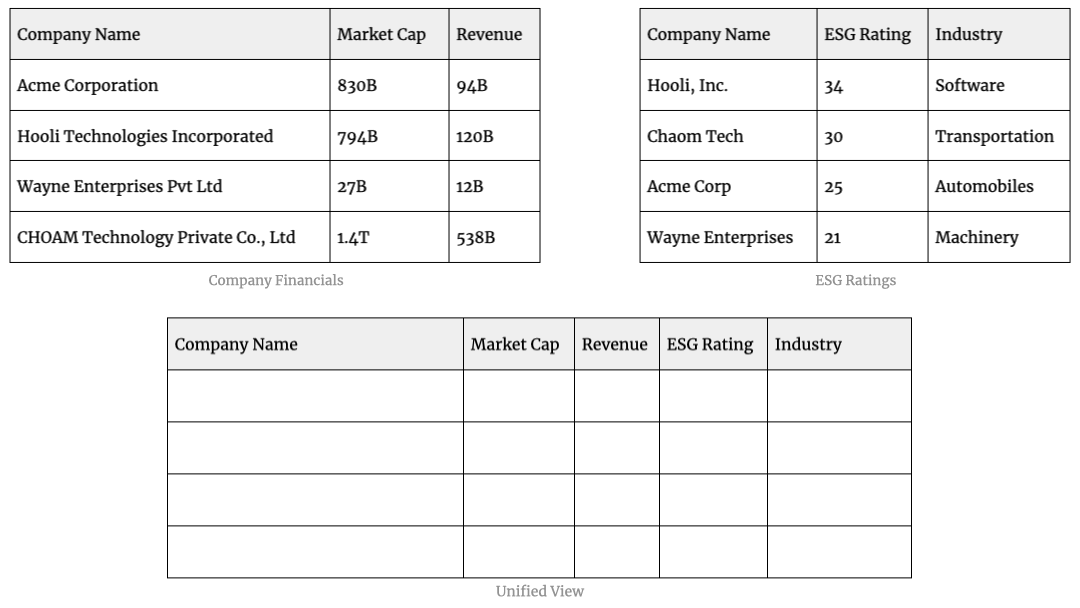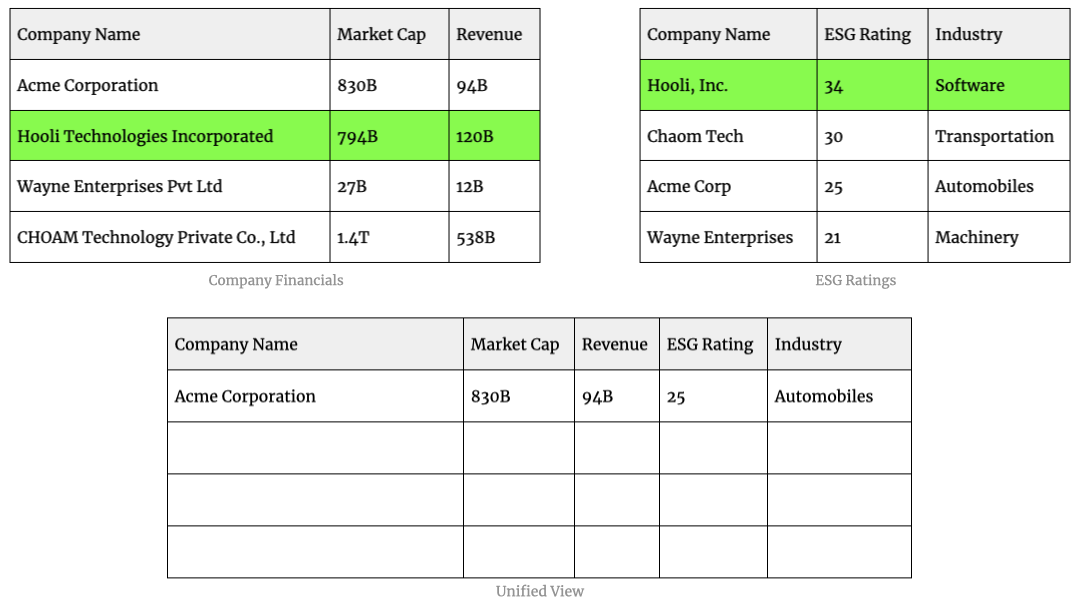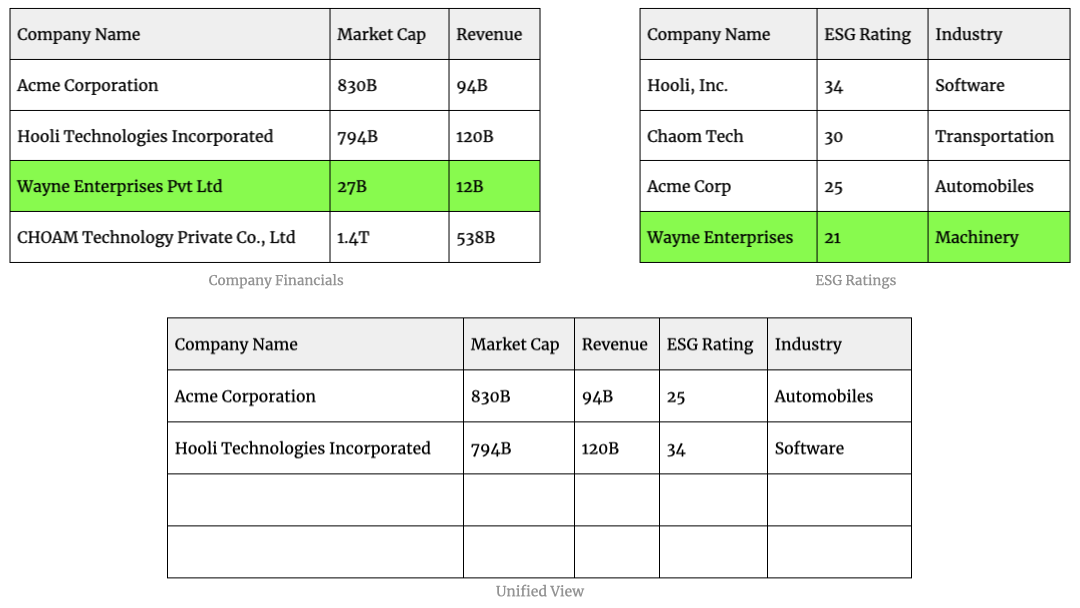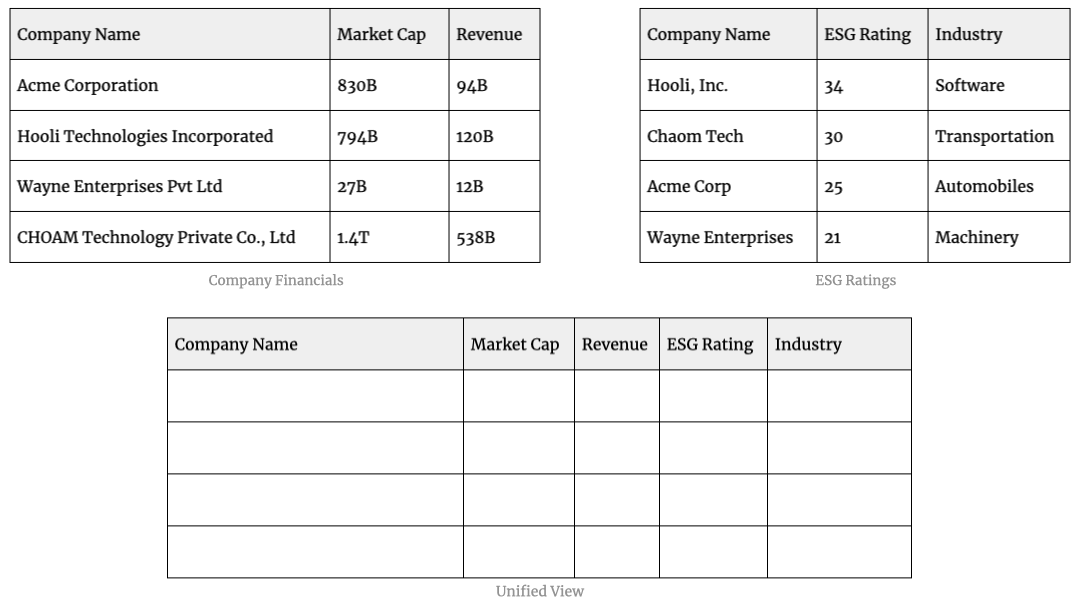
For example, if you have the following datasets containing information about companies:
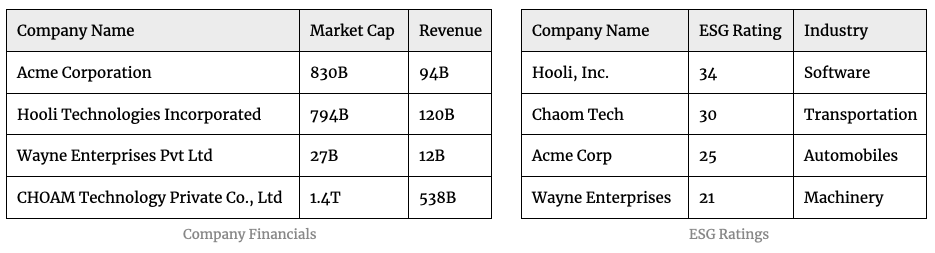
You’ll be able to get better insights if you combine the data from both the datasets instead of looking at each dataset in isolation.
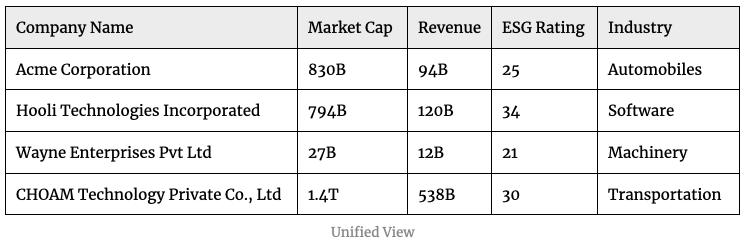
No unique identifiers
You might be wondering what makes this process challenging - can’t we just do a SQL join on the datasets based on a unique identifier like SSN (for people) or stock tickers (for companies)?
Unfortunately, not all datasets come with unique identifiers. Even if they do have unique identifiers, it might be that they are different - one dataset might contain SSN and other might have University Student ID.
Attributes like person’s name, date of birth etc can’t be used as unique identifiers either.
For example, we normally assume date of birth to be somewhat unique among the population and that it’s rare for 2 people to have the same birthday. There are 365 days in a year, so there’s only 365 unique date of births - it’s actually not that unique. Even so, we intuitively think that we need a group of at least 365 people for 2 of them to have the same birthday. But if we do the math, we see that we only need a group of 70 people for 2 of them to have 99.9% chance of same birthday! Birthdays are even less unique than we thought it was. This is known as the birthday paradox, and this holds true for other attributes as well.
If we don’t have unique identifiers (SSN), and we can’t rely on non-unique identifiers (date of birth), what else can we use?
We can use a combination of non-unique identifiers as a “composite identifier”. For example, we can use person’s first name + last name + date of birth + gender as a composite identifier.
Conflicting data
While this approach make sense, there are still some limitations depending on the data sources you use:
Outdated data
People change their names, their addresses etc. Companies might have gone through mergers or acquisitions which could have resulted in significant changes to the data. These changes might be captured in one data source but not in others.
Inconsistent data
Depending on the way the data is gathered, someone might have entered their nickname in one data source but their full name in another. One data source might contain the company’s legal name but the other might have DBA (Doing Business As) name. If there’s no mapping available between these alternative representations, then it’s hard to reconcile.
Missing data
Important attributes that could’ve been part of the composite identifier might have a lot of NULL values in either of the datasets.
Dirty data
There could be typos and other mistakes while gathering the data.
Fake data
Some users might intentionally provide wrong information.
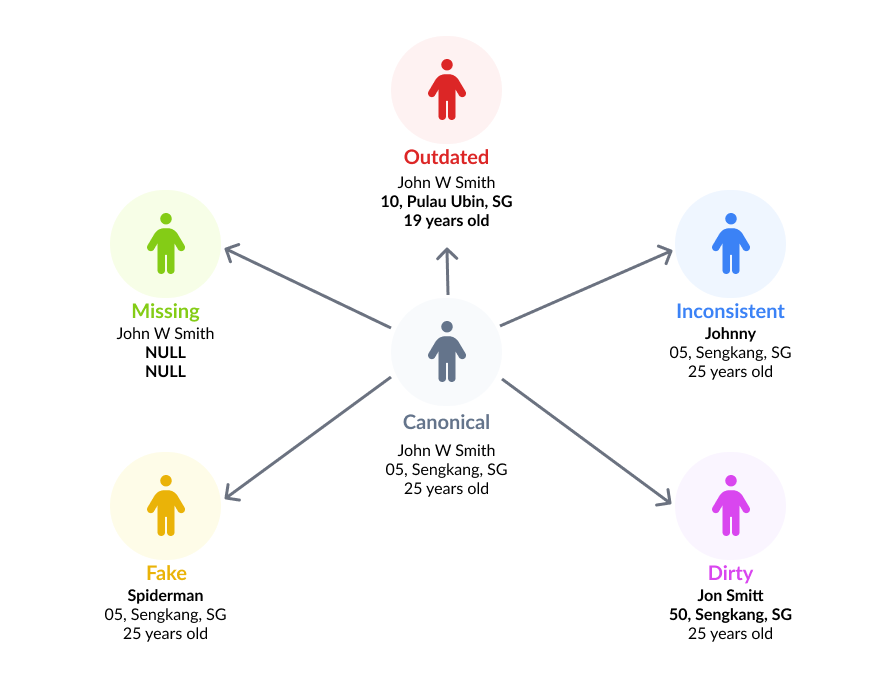
These inconsistencies reduce the effectiveness of using the composite identifiers, but most of the time, they’re all we would have to work with.
Scalability
Aside from data quality issues, the size of the datasets also pose a challenge. We need to do a pairwise comparison between the records of the two datasets and decide whether they match or not.
This pairwise comparison scales quadratically - if you have m number of records in one dataset and n number of records in the other, then the number of comparisons is m * n. If you remove duplicates, it becomes (m * n) / 2.
Big O notation doesn’t care about exact values and is only concerned about how an algorithm scales with the size of data. So we make m and n the same and remove the constant 1/2. The number of comparisons become n * n which is n² or quadratic complexity.
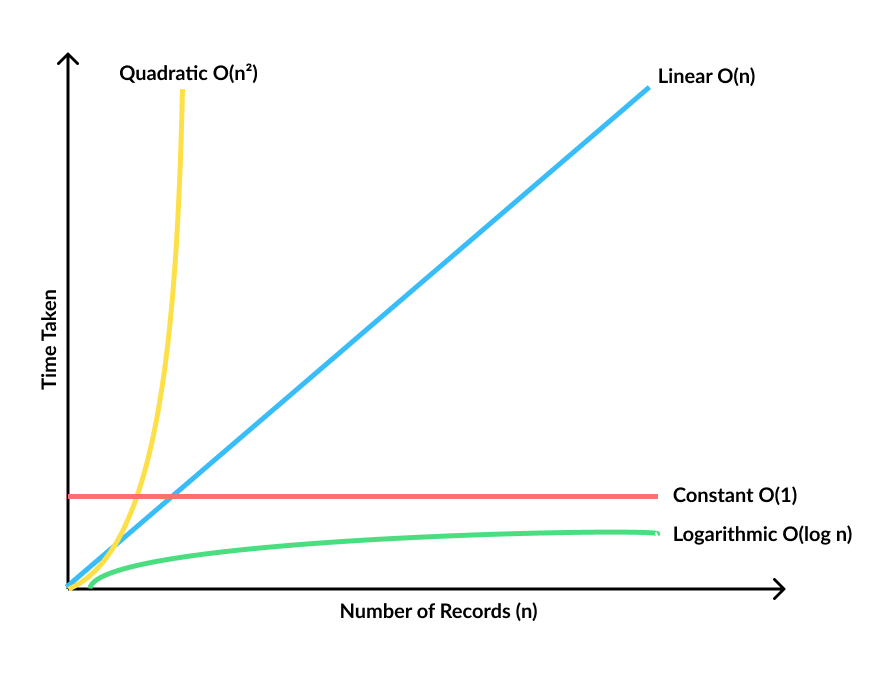
In order to give a sense of how bad this is, let’s say the n is 100,000 records. If the comparison algorithm takes about 0.05 milliseconds, then 100,000 * 100,000 comparisons * 0.05 milliseconds = 5.79 days!
| Number of Records | Time Taken |
|---|---|
| 1000 | 50 seconds |
| 10,000 | 1.3 hours |
| 100,000 | 5.8 days |
| 1,000,000 | 1.6 years |
| 10,000,000 | 158 years |
Conclusion
Depending on the datasets you’re dealing with, entity resolution task can be as trivial as an SQL join (if you have unique identifiers and good quality data), or a comfortable challenge (large scale and good quality data), or an impossibly wicked obstacle to overcome (large scale and bad quality data).
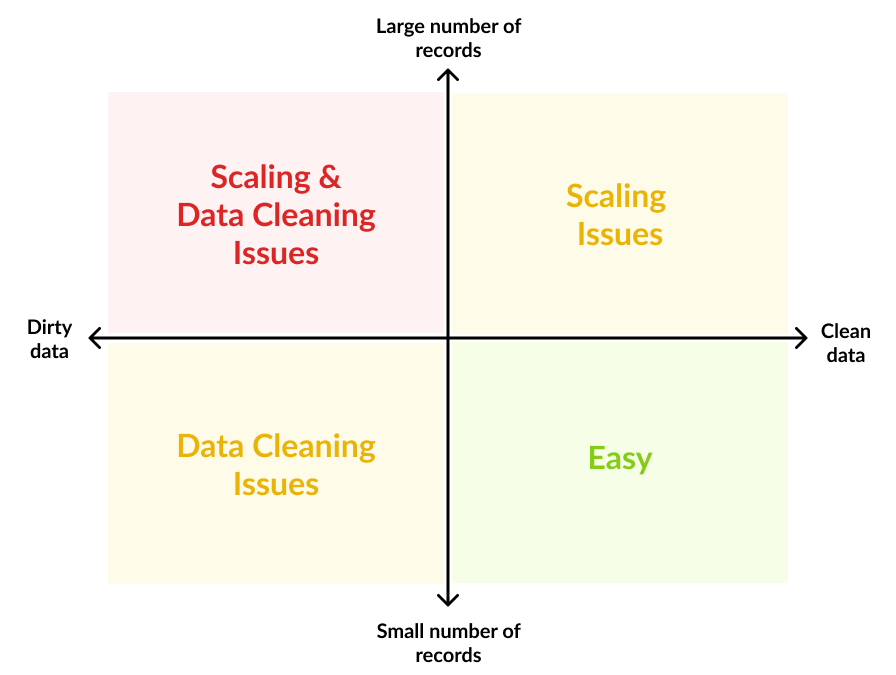
Luckily this is not a novel problem, very smart people around the world have spent many years trying to solve this problem. They have come up with many solutions for solving the above challenges. I will go through some of them in future posts.