A Gentle Introduction to LLMs for Product Teams
There has been explosive growth in Generative AI and LLMs (Large Language Models) in the past few months. Not only we are seeing the launch of new products like ChatGPT, Midjourney etc, we also see established products like Notion, GitHub, etc incorporating LLMs to provide new features to users.
If you’re working in a product team as a designer, product manager or a non-ML developer, you might be wondering if you can use LLMs in your products. But it might have been hard to understand the terminologies like “memory”, “tokens”, “langchain” etc or know what the capabilities and limitations of these LLMs are.
In this post, I’ll try to explain LLMs in an easy to understand manner.
Prompts and Prompt Engineering
Let’s start with something most of us are familiar with - ChatGPT. We ask it a question and it gives an answer. We ask a followup question and it gives another answer. The questions we ask the LLMs are called “prompts”.
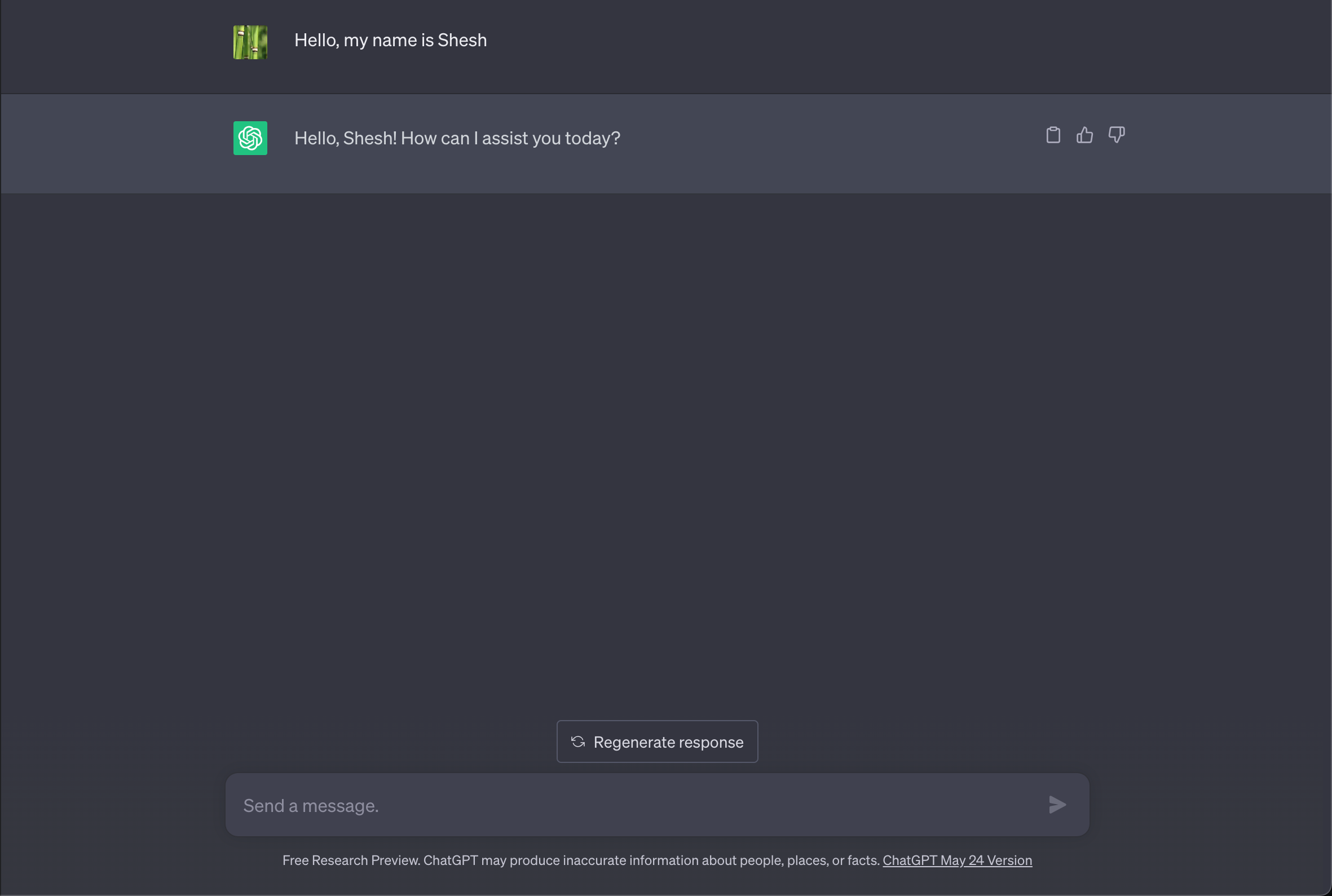
You might have noticed that you can also ask it to change the way it answers. You can ask it to make the answer concise, change the tone to be professional, etc. You can also use more advanced techniques like using examples to getter better answers, asking the model to do step-by-step reasoning, reduce hallucinations etc. These methods of manipulating the LLM’s output by wording your prompts differently or adding instructions is called “prompt engineering”.
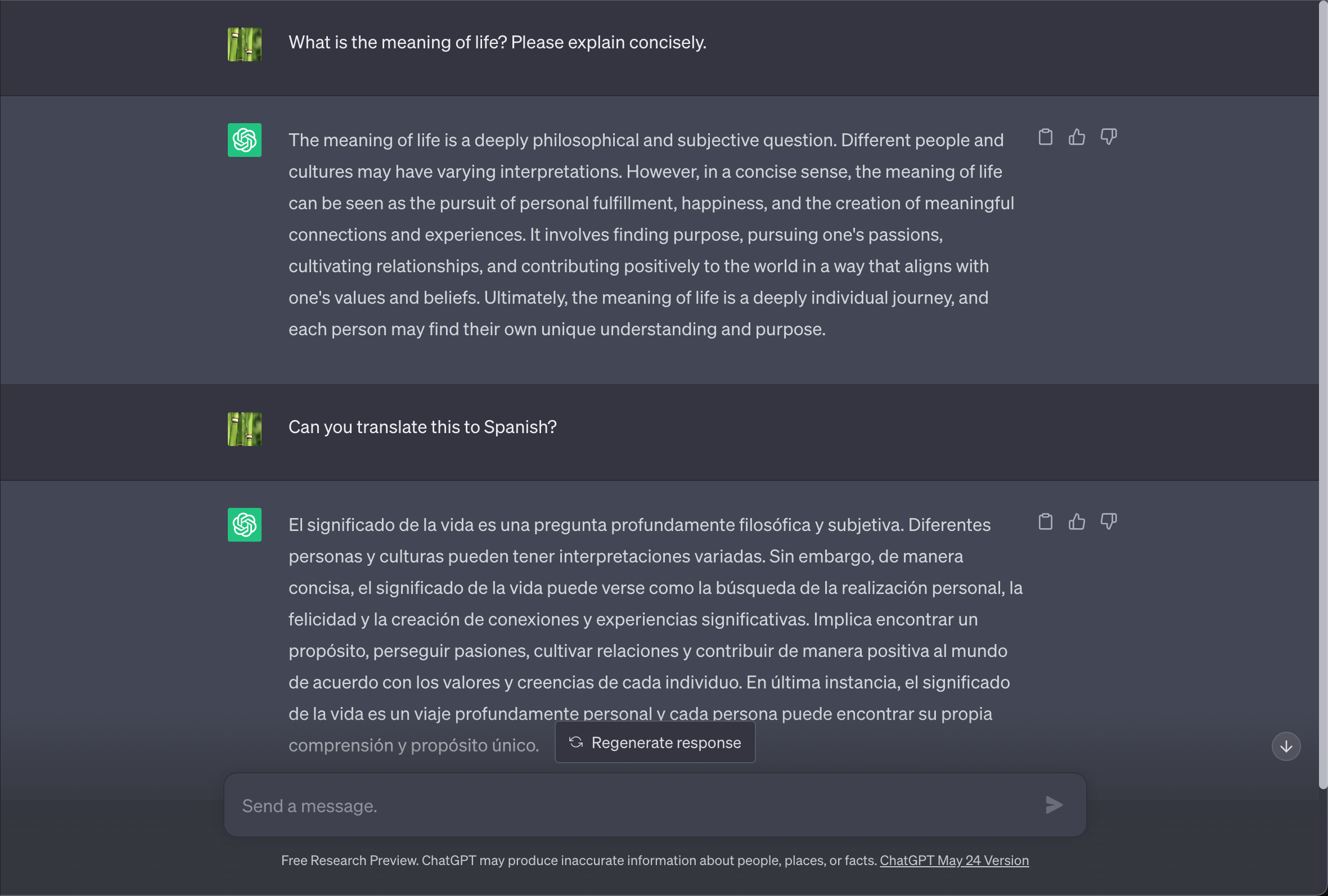
Token Limits
When we build applications, we usually add restrictions on the user inputs. For example, we might make the username field to be max 100 characters, or the product review written by the user to have max 1000 characters etc.
LLMs have similar restrictions, but instead of measuring in number of characters, they measure in number of “tokens”. To put it simply, a “token” is either a word or partial word. Here’s an example of how the sentence “Premature optimization is the root of all evil.” is split into tokens using the OpenAI Tokenizer tool:
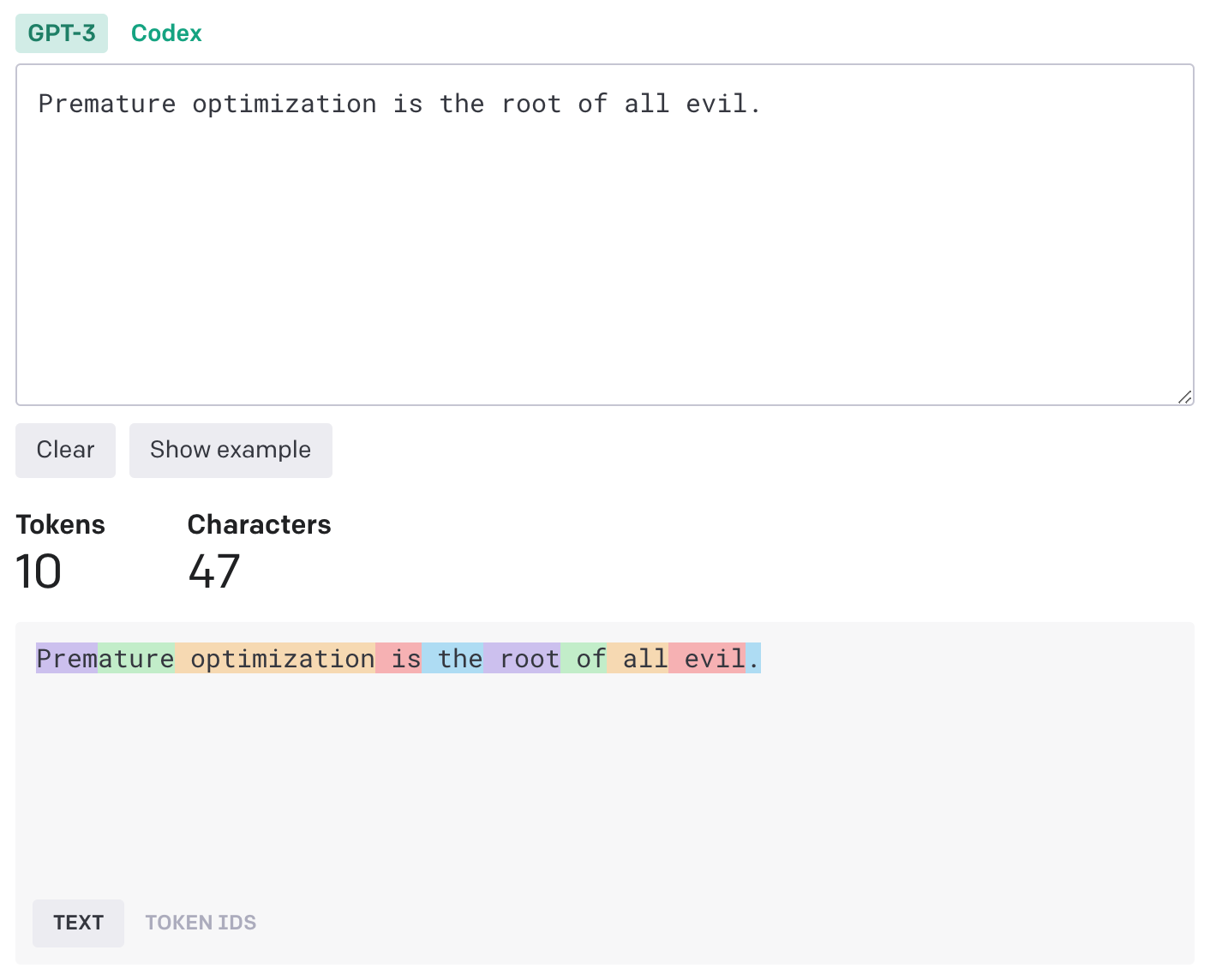
The sentence contains 8 words but it’s split into 10 tokens. Notice how the first word is split into two tokens, and how the period at the end is its own token.
A good rule of thumb is to think of a token as 3/4th of a word. So 75 words are 100 tokens.
Some models like gpt-3.5-turbo have 4096 max token limit (~ 3000 words), some like gpt-4-32k have 32,768 (~ 25,000 words). And this token limit affects both the input and output of the model. If the input takes up most of the token limit, there’s less number of tokens available for the model to output.
Memory and Stateless Models
One thing we don’t notice about ChatGPT is how it remembers what we tell it. We don’t notice this as it’s an intuitive behavior - if we’re chatting with our friend, we expect them to remember what we told them before. Notice how it remembers my name:
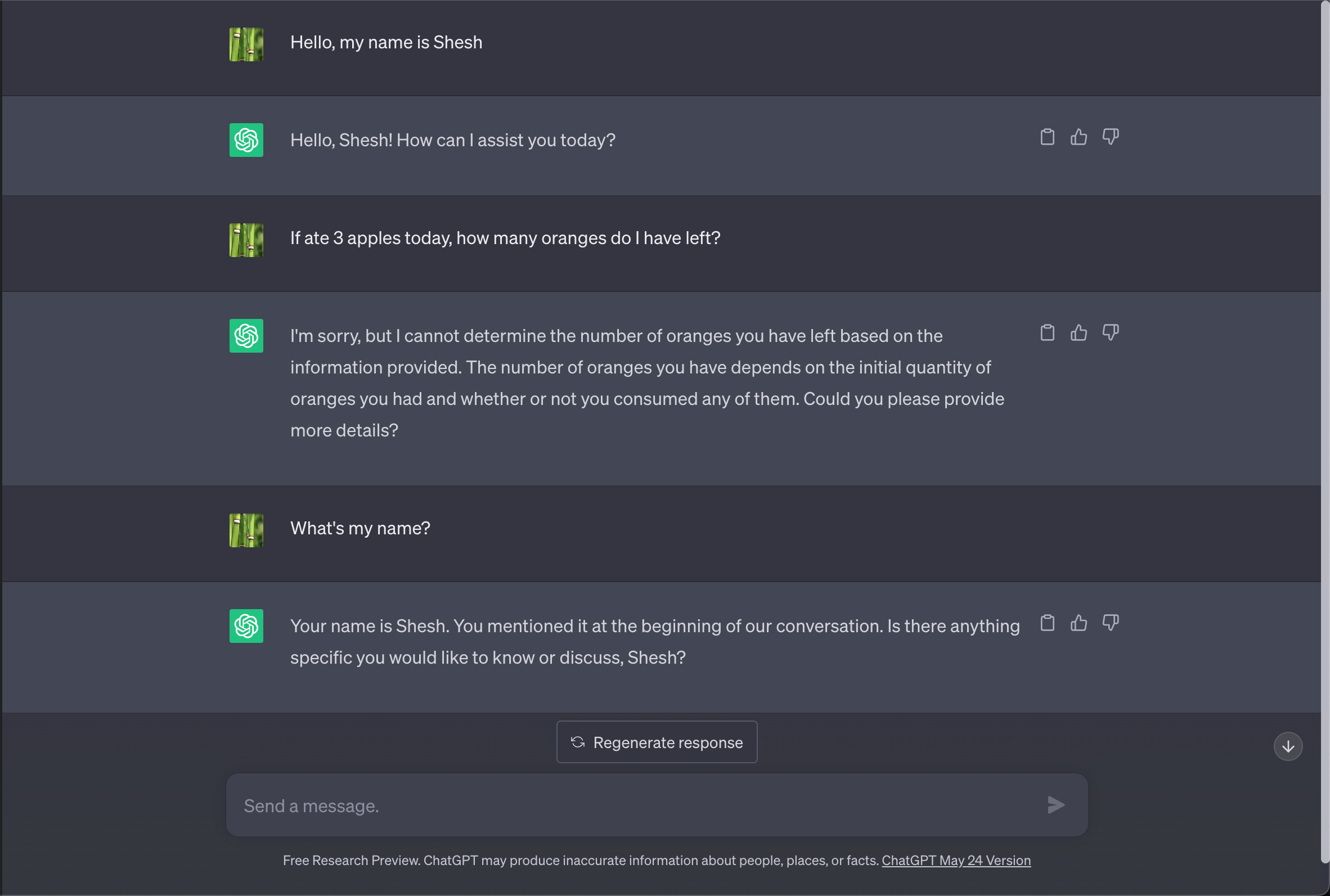
But LLMs are actually stateless - they have no memory of previous conversation! Then how do they “remember” what we said before? It’s because ChatGPT passes the previous conversation history along with the latest question. As you can imagine, this approach only works to some extent until you start hitting the token limits.
Consequence of Stateless Models and Token Limits
At the risk of oversimplifying, most applications we build basically have a database and a frontend for the users to update/query the database. If you’re working on such a product, your immediate instinct is to see if you can replace/augment your frontend with a chat interface so your users can update/query your database by “chatting” with an LLM.
But how does the LLM know the structure of your database - what columns it has, the format of the data inside them, etc? Should we just dump the contents of the database into a prompt and ask it follow up questions? From what we know of token limits, this is not possible unless your database is tiny. You also can’t ask it to memorize the database in one prompt and ask followup questions.
People have come up with creative workarounds for this problem:
- Instead of dumping the entire database into the prompt, we can include our database schema and a few example records so it can generate a SQL query for us to query the database on its behalf.
- Same goes for documents - instead of feeding it documents, we can search the documents based on the user’s prompt, retrieve the relevant passage from the document, add it to the user prompt and finally ask the LLM to reformat the document passage based on the user’s prompt.
These techniques are known as “Retrieval-Augmented Generation”.
Data Privacy
If your product deals with sensitive information like PII, health records etc, more care should be taken while using LLMs. The data passed in prompts can be leaked if not stored properly or it can be used for training the model which could be leaked to other users when they ask similar questions.
Hallucination
Sometimes, LLMs can give confidently wrong answers. While this might be acceptable in some scenarios, this severely limits their usefulness when you want to integrate them into your product.
LangChain
It’s a library for building applications powered by LLMs. You can think of it similar to using React for UI or Rails for Backend apps etc. It simplifies the development of LLM apps by providing useful features like prompt templates, memory, agents etc and allow us to compose (chain) these features together to build a workflow.
Agents
LLMs are good with reasoning and language skills. We can ask a question, if the details provided are insufficient, the LLM asks a clarifying question, we can answer its questions to get the final answer:
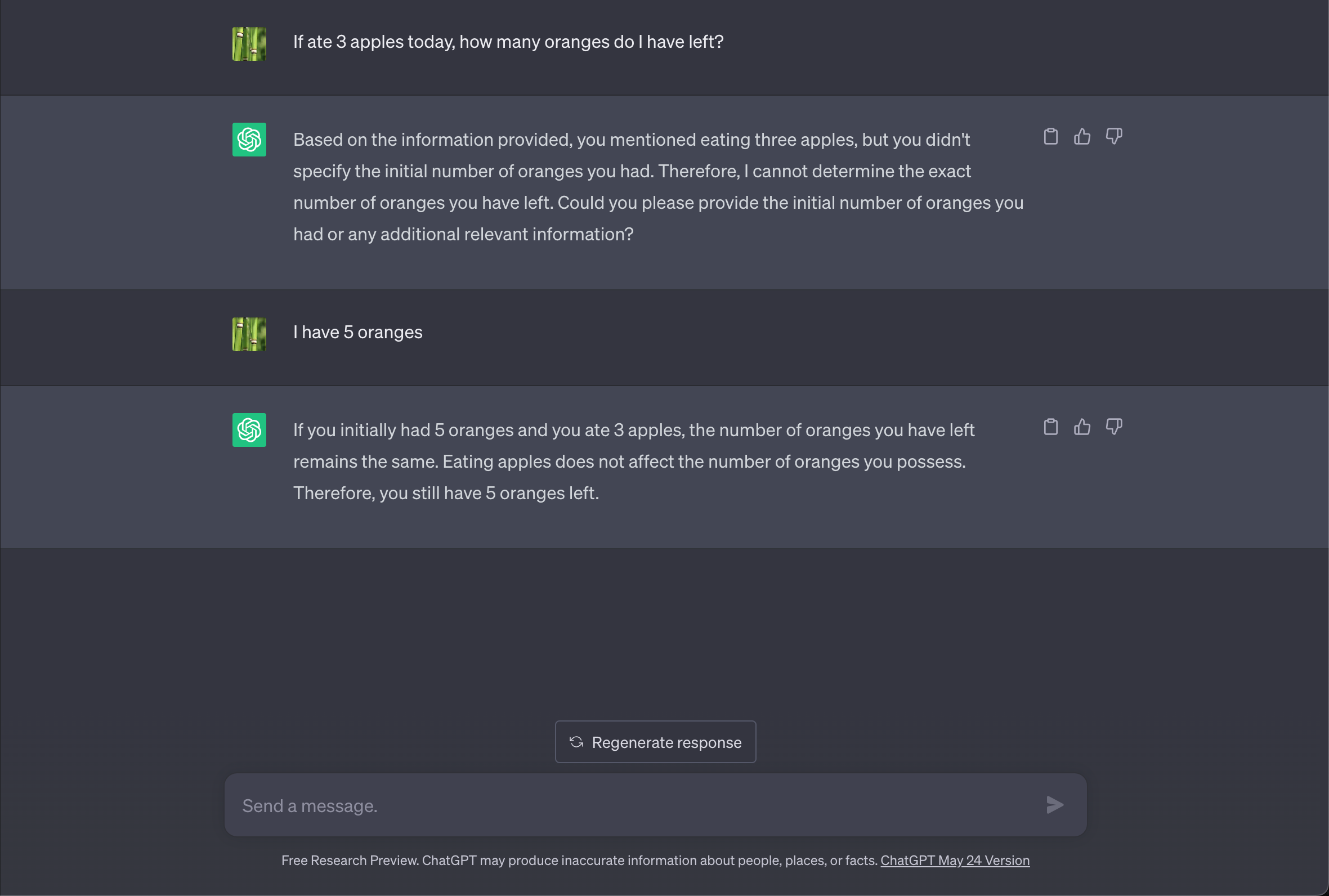
What if we remove ourselves from the above flow? What if it can use “tools” like search Wikipedia, make API calls, or run a Python script? What if we can combine both the reasoning and the ability to use “tools”? This is called an “agent”.
Conclusion
Understanding the capabilities and limitations of LLMs can help us better evaluate how to integrate it into our products. It’s important to note that this is a fast moving space, so some of these limitations might be solved at the model level or new products could come up to mitigate the concerns. It’s helpful to keep up with these advancements so we can make the right decisions and tradeoffs.